
Abstract: Inherent morphological characteristics in objects may offer a wide range of plausible grasping orientations that obfuscates the visual learning of robotic grasping. Existing grasp generation approaches are cursed to construct discontinuous grasp maps by aggregating annotations for drastically different orientations per grasping point. Moreover, current methods generate grasp candidates across a single direction in the robot’s viewpoint, ignoring its feasibility constraints. In this paper, we propose a novel augmented grasp map representation, suitable for pixel-wise synthesis, that locally disentangles grasping orientations by partitioning the angle space into multiple bins. Furthermore, we introduce the ORientation AtteNtive Grasp synthEsis (ORANGE) framework, that jointly addresses classification into orientation bins and angle-value regression. The bin-wise orientation maps further serve as an attention mechanism for areas with higher graspability, i.e. probability of being an actual grasp point. We report new state-of-the-art 94.71% performance on Jacquard, with a simple U-Net using only depth images, outperforming even multi-modal approaches. Subsequent qualitative results with a real bi-manual robot validate ORANGE’s effectiveness in generating grasps for multiple orientations, hence allowing planning grasps that are feasible.
Source: https://arxiv.org/abs/2006.05123
GitHub: https://github.com/nickgkan/orange

Open-loop grasp performance with a bi-manual manipulator 
PyBullet Grasp environment. The grasp is detected through ORANGE-UNet and executed through open-loop planning.
In this work, we tackle the problem of disentangling the possible orientations per grasp point. To this end, we propose a novel augmented grasp representation that parses annotated grasps into multiple orientation bins. Stemming from this representation, we introduce an orientation-attentive method for predicting pixel-wise grasp configurations from depth images. We classify the grasps according to their orientations into discrete bins, while we regress their values for continuous estimation of the grasp orientation per bin.
Moreover, this orientation map acts as a bin-wise attention mechanism over the grasp quality map, to teach a CNN-based model to focus its attention on the actual grasp points of the object. The proposed method, named ORANGE (ORientation AtteNtive Grasp synthEsis), is model-agnostic, as it can be interleaved with any CNN-based approach capable of performing segmentation while boosting their performance for improved grasp predictions. ORANGE achieves state-of-the-art results on the most challenging grasping dataset, acquiring 94.71% using only the depth modality, against all other related methods. Knowledge from ORANGE can also be easily transferred and leads to significantly accurate predictions on the much smaller dataset Cornell. Moreover, our analysis is supported by robotic experiments, both in simulation and with a real robot. Our physical experiments show the importance of disentangling the grasp orientation for achieving an efficient robot grasp planning while also highlighting other parameters that affect the grasp success.
What is a grasp map?
A grasp map was first introduced in [1] as a way of relating discrete grasp points over the depth map of an object. Particularly, a planar grasp 
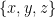
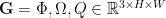
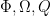
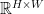
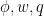


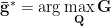
Why is this representation problematic? The grasp maps constructed by current pixel-wise learning approaches [1-4] are prone to discontinuities that cause performance to saturate, due to the overlapping grasping orientations per point. Motivated by the need of acquiring approaching grasp vectors from multiple orientations, we introduce an augmented grasp map representation, that fuels both the continuous orientation estimation, commonly treated as a regression problem, and a discrete classification.
Let’s take as example the Jacquard dataset. Jacquard is currently one of the most diverse and densely annotated grasping datasets with 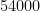
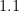

Augmented grasp map representation:
We part from recent approaches on pixel-wise grasp synthesis and partition the angle values into 



Note, however, that we do not discretize the angles’ values: we instead place them inside the corresponding bins. For the remaining overlaps, we pick the value with the smallest angle, ensuring that the network is trained on a valid GT angle value, instead of some statistics of multiple values (e.g. mean or median), while remaining invariant to the order of the annotations.

To overcome the information loss from constructing binary maps, we create soft quality maps that contain ones on the exact positions of the centers of the boxes, while their values degrade moving towards the boxes’ edges. We find this significant for the networks to learn to maximize the quality value on the actual grasp points, and do not acquire strong Gaussian filtering [1] and consequently reduces post-processing time. One remaining issue is the multiple instances of the same grasp centers and angles using different jaw sizes. We construct our augmented maps picking the smallest jaw size available, i.e. closer to the boundaries of the objects’ shape. Intuitively, the annotated quality map gives a rough estimate of the object’s segmentation mask, which appears important for extracting grasp regions. During evaluation, we adopt the half jaw size as in [1] to be directly comparable. Although having to estimate this parameter hurts performance, our approach still achieves large reconstruction ability.
We reformulate the previous grasp map formalization to consider 
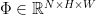
For facilitating learning, we adopt the angle encoding suggested by [6] into the cosine, sine components that lie in the range of ![[-1, 1]](https://s0.wp.com/latex.php?latex=%5B-1%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)




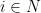





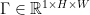

ORANGE architecture: The proposed framework is model-agnostic; it suffices to employ any CNN-based model that has the capacity to segment regions of interest. Then, an initial depth image is processed to output an augmented grasp map 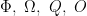

Training: Each map is separately supervised: we minimize the Mean Square Error (MSE) of the real-valued 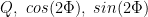
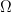
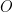

Inference: First, 
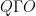


Model zoo: We embed ORANGE to two off-the-shelf architectures, GGCNN2 [1] and the larger U-Net [7], as both able of performing segmentation. While these models have totally different capacity, we show that both can perform significantly better when trained with ORANGE. As we are mainly focusing on the advantages of the grasp orientation disentanglement, we consider that any deep network capable of segmentation, can benefit from the ORANGE framework.
Why does it matter to disentangle overlapping grasps for grasp planning?
We conducted experiments with the bi-manual mobile manipulator robot TIAGo++, which is equipped with one gripper and a five-fingered underactuated hand. We leverage our robot’s properties to study how the different orientations in the grasp maps can enable a successful robot grasp.
For this experiment, we chose a set of five objects from the YCB object set, for which we conduct 
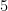


Note that this experiment is more challenging than usual bin-picking experiments: the camera viewpoint is much different than that of the training dataset setting, as well as compared to other related robotic experiments, that install a static camera facing the table vertically and plan planar pinching grasps. We, on the other hand, plan open-loop collision-free trajectories considering the robot’s arm and torso motion for planning the trajectory towards a generated target grasp vector by ORANGE. A grasp is successful when the robot holds the object in the air for
For this experiment, we collect the best grasp point across all bins (i.e., for all predicted orientations) and attempt the ones that are within the feasibility set of the workspace of each arm to showcase the importance of parsing the possible grasp angles.
While with the gripper we are able to grasp most objects (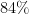
Next steps: The results of this experiment highlight two findings: (i) the advantage of acquiring a disentanglement of the potential grasp orientations provides a promising framework for planning feasible robot grasps, especially with bi-manual and mobile manipulator robots. A possible future research direction concerns the learning of a policy for selecting the grasp points per orientation; (ii) a good visual grasp generator can only be a good indicator for a successful grasp. We believe that a combination of the effectiveness of ORANGE fused with tactile feedback can potentially provide a more powerful tool for effective grasping.
References:
[1] D. Morrison, P. Corke, and J. Leitner, “Learning robust, real-time, reactive robotic grasping,” IJRR, vol. 39, no. 2-3, 2020. [2] Y. Song, J. Wen, Y. Fei, and C. Yu, “Deep robotic prediction with hierarchical rgb-d fusion,” arXiv preprint arXiv:1909.06585, 2019.
[3] S. Wang, X. Jiang, J. Zhao, X. Wang, W. Zhou, and Y. Liu, “Efficient fully convolution neural network for generating pixel wise robotic grasps with high resolution images,” in IEEE Int’l Conf. on Robotics and Biomimetics, Dec 2019.
[4] S. Kumra, S. Joshi, and F. Sahin, “Antipodal robotic grasping using generative residual convolutional neural network,” arXiv preprint arXiv:1909.04810, 2019. [5] F. Chu, R. Xu, and P. A. Vela, “Real-world multiobject, multigrasp detection,” IEEE Robotics & Automation Letters (R-AL), vol. 3, no. 4, Oct 2018. [6] Hara, K., Vemulapalli, R. and Chellappa, R., “Designing deep convolutional neural networks for continuous object orientation estimation,” arXiv preprint arXiv:1702.01499, 2017 [7] O. Ronneberger, P.Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in Medical Image Computing and Computer-Assisted Intervention (MICCAI), ser. LNCS, vol. 9351.Springer, 2015.
Work conducted with Nikolaos Gkanatsios (CMU), Petros Maragos (NTUA), Jan Peters (TU Darmstadt)